【Node.js】mongoose教程10--聚合(Aggregation)的应用
本文是存储了5个手机数据后再操作的。存储实现见文章:【Node.js】mongoose教程–存储。
GitHub源码链接:sodino#MongoDemo
聚合操作(Aggregation Operation)
官方文档链接:
Aggregation
Aggregation Pipeline Quick Reference
Aggregation Pipeline Operator
Aggregation Commands Comparison
官方是这么描述聚合操作的:
1 | Aggregations operations process data records and return computed results. |
Sodino勉强翻译一下吧:聚合操作能够处理数据记录并返回处理后的计算结果。聚合操作能够将多个文档记录的值重新划分组别,并在重新分组的数据上执行丰富的计算操作然后返回单一的计算结果。
翻译成大白话就是:聚合操作能够在MongoDB层面进行数据加工、数据挖掘,产生新的有价值的数据记录。
举个例子:
之前的文章mongoose教程07–排重与计数就是聚合操作在实际应用中的例子。
从存储的数据文档中重新计算出了厂商国家数量及符合条件的手机型号数量,这些信息是间接通过已存储的字段加工后挖掘出来的。
MongoDB提供了聚合操作的三种方式:
Aggregation Pipeline
Map-Reduce
Single Purpose Aggregation Operations
三种方式各自的函数名称汇总如下表:
| 聚合归类 | 函数名称 |
|---|---|
| Aggregation Pipeline | Model.aggregate() |
| Map-Reduce | Model.mapReduce() |
| Single Purpose | Model.count() Model.distinct() Model.group() |
上文的排重和计数就属于Single Purpose Aggregation Operations,当然还有群组 group()未提及到。
接下来讲一下聚合三种操作中的Aggregation Pipeline及应用场景一例。
聚合管道(Aggregation Pipeline)
MongoDB的聚合框架实现是模仿Data processing pipeline。数据文档进入多级管道并将文档转换为聚合结果。
聚合管道最基础的功能包括提供类似于查询的过滤器;数据文档转换,能调整聚合结果所输出的文档数据的结构,如在聚合的结果中新增加原始数据文档中没有的字段,如数组长度、组合名称等有价值的字段。
还有另外的功能,包括按数据文档的字段进行分组或排序,对数组或成批的数据文档进行再处理,还包括计算平均数、连接/截取字符串等功能。
聚合管道还支持索引等功能。
为了实现以上功能,引入了聚合管道操作符(Aggregation Pipeline Operators)的概念。
操作符分为三类:
- Stage Operators
- Expression Operators
- Accumulators
三类操作符各自分类见下图
找出安装了最多应用的手机
直接以例子来讲聚合管道的应用吧。
在mongoose教程–存储中,存储了5种手机数据,想找出安装了最多应用的手机数据,该怎么做?
首先,这是要求MongoDB按数组长度进行排序的功能,分解需求:
- 要获取每个apps数组的长度
- 数组长度在聚合结果中要有字段名,即新增字段
- 按新增字段进行排序
- 对apps进行空数据兼容
通过阅读文档,涉及到管道操作符知识点直接列出如下:
$project: 定义查询后的聚合结果,即新增加字段apps_count,以便排序。
$size: 对数组的长度取值
$ifNull: 空数据兼容
$sort: 排序
下面先直接给出实现代码然后再逐一说明:
1 | function findThePhoneWithMostAppsInstalled() { |
控制台输出: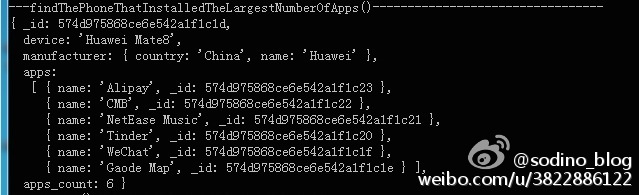
$project
$project能够将数据文档指定的字段传给管道做下一步处理,指定的字段可以是数据文档中原有的字段,也可以是新计算出来的自定义字段。
$project的原型表达式如下:
1 | { $project: { <specifications> } } |
其中<specifications>可以是以下三种形式:
| 语法 | 描述 |
|---|---|
| < filed > : < 1 or true> | 指定要包含的字段 |
| _id : < 0 or false> | 不处理_id字段 |
| < field >: < expression > | 新增的自定义字段或修改掉原有字段的值 |
所以,在上面的代码中:
1 | {$project : |
共定义了这次聚合操作后要返回的4个字段:
- apps_count : 新增加的数组长度字段。
- device : 原有的
device字段,值为1表示要包含在查询结果中。 - manufacturer : 原有的
manufacturer字段,值为1表示要包含在查询结果中。 - apps : 原有的
apps字段,值为1表示要包含在查询结果中。
$size
用于计算数组的长度。
它的原型表达式如下:
1 | { $size: <expression> } |
其中expression可以是从数据文档中现有的数组,也可以是运算后的新数组:
使用$取值符获取数据文档中现有的数组字段用例如下:
1 | { |
以上的代码将返回聚合结果为:
1 | {device : `Huawei Mate8`, |
但由于并非所有的数据文档的数组字段都存在或者都有数据,就需要使用$ifNull进行错误兼容了。见下节$ifNull。
要注意的是MongoDB中有两个$size操作符,它们的含义是不一样的,
第一个$size是在查询时用于匹配指定长度的数组;第二个$size用于聚合管道中计算数组的长度。
见下图:
$ifNull
$ifNull原型表达式如下:
1 | { $ifNull: [ <expression>, <replacement-expression-if-null> ] } |
该操作符功能是计算表达式expression,如果expression的计算结果为非空值,则返回该非空值;如果为空值或者是undefined或者计算失败,则使用replacement-expression-if-null这个表达式的结果来代替。
当然,expression可以是计算表达式,也可以直接是数据本身。如下举例:
1 | { |
当发现数据文档中没有device字段时,直接返回字符串Unknown。
$sort
$sort原型表达式如下:
1 | { $sort: { <field1>: <sort order>, <field2>: <sort order> ... } } |
对输入的数据文档按指定的field1、field2进行排序。sort order的值只能是1表示该字段值按升序排序或-1该字段值按降序排序。