【JavaScript】正则表达式删除代码注释 约定:本文中,以数字内容表示代码正文,其余字符内容表示注释内容。
代码注释有三种形式:
第一种:
第二种:
1 123456 /* aabbccdd */ 123456
第三种:
1 2 3 123456 /* aabbccdd * aabbccdd * * aabbccdd */ 123456
其实第二种和第三种是同一类型。
代码实现与运行效果 直接给代码,看运行效果,然后再来讲正则表达式为什么要这么写.
代码实现如下:
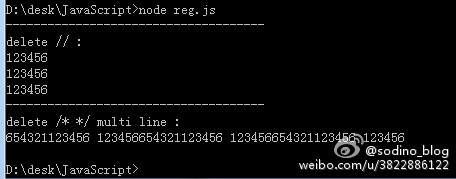
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 function deleteCodeComments(code) { // 以下的两种方式都可以 // sodino.com // var reg1 = /\/\/.*/g; // var reg2 = /\/\*[\s\S]*?\*\//g; var reg = /(\/\/.*)|(\/\*[\s\S]*?\*\/)/g; var result = // code.replace(reg1, '').replace(reg2, ''); code.replace(reg, ''); return result; } string = '123456 //aabbccddee'; string = string + '\n\r' + string + '\n\r' + string; // result = string.replace(/\/\/.*/g, ""); result = deleteCodeComments(string); console.log('-------------------------------------'); console.log('delete // :'); console.log(result); string = '654321/* aabbccdd */123456/* aabbcc' + '\n\r' + '* aabbcc *' + '\n\r' + '* aabbcc *' + '\n\r' + '* aabbcc **/ 123456'; string = string + string + string; // result = string.replace(/\/\*[.\s\S]*?\*\//g, ''); // sodino.com result = deleteCodeComments(string); console.log('-------------------------------------'); console.log('delete /* */ multi line :'); console.log(result);
控制台输出如下:
单行注释 // 的处理 代码的每一行中,双斜杆//及其后内容,不管是任何字符,都是注释。//开始,后续不论任何字符都直接可以删除。
开头的//表示遇到//就开始匹配,.表示//后可匹配的字符内容为除了换行符以外的任意一个字符,*表示//后面符合条件的字符出现次数可以为0或任意次数。//在JavaScript中需要转义,所以在定义时转义后的表达式如下:
1 2 // 原型是://.* var reg1 = /\/\/.*/;
使用该表达式匹配代码,会发现只有第一次出现的的注释会被删除,第二个及以后的注释都还在。好吧…需要再添加全局匹配功能,即添加g。代码如下:
这样,不论代码中出现多少行 // 注释,都可以被一一匹配出现替换掉了。
多行注释 /* */的处理 /* */的特殊之处在于它可以单行注释,也可以多行注释,所以比//要多过滤掉换行符,所以在//中的.只代表非换行符的其它所有字符,所以.就不能用了。
看看正规表达式语法规范 中,可以用\s和\S的合集来表示所有的字符。
字符
含义
\s
匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
\S
匹配任何非空白字符。等价于[^ \f\n\r\t\v]。
合集的表示用[]将\s\S包含在内即可。所以改进一下,初始的表达式如下:
1 2 // 原型是:/*[\s\S]**/ var reg2 = /\/\*[\s\S]*\*\//g;
即以/*开始,以*/结尾,中间的任意字符的组合都符合匹配规则。当然,/*及*/在上面的表达式中都用转义字符\转义了。
但上面的表达式还有问题。当遇到如下的代码,
1 123456/* aabbc */ 123 /* aabbcc */ 456
匹配的结束字符串*/有两个,那么每次匹配时,该告诉解释器以该选择哪个呢?
贪婪模式即尽可能的去匹配更多符合条件的字符内容,在上面的例子中,即匹配到*/ 456才结束,运算之后的结果将会是:123456 456。*/ 123结束,运算的结果将会是123456 123 456。
很明显,这种场景下我们需要的是非贪婪模式。正规表达式语法规范 ,可以用?来使用非贪婪模式,所以最后的改进代码如下:
1 2 // 原型是:/*[\s\S]*?*/ var reg2 = /\/\*[\s\S]*?\*\//g;
整合 当然,我们也可以通过 |串接起两个匹配规则。相当于’或‘运算。串接后的正规表达示如下:
1 var reg = /(\/\/.*)|(\/\*[\s\S]*?\*\/)/g;
单行注释要排除 http:// 等## 在使用过程中,发现上文中的单行注释会把 http:// 或 ftp:// 等字符串定义一并当做注释处理掉了。http://的干扰项的源字符串,及当前过滤出的错误结果及期待的正确结果。
1 2 3 4 5 6 7 123456"http://sodino.com" // aabbccdd // 错误的结果: 123456http: // 期待的正确结果: 123456"http://sodino.com"
很可惜,JavaScript并不支持正则表达式中的反向否定预查 ,那只好再想想办法。
查看JavaScript文档,发现String.prototype.replace(regexp|substr, newSubStr|function) 的第二个参数是支持函数的。即目标替换符可以通过函数来按自定义的逻辑来决定,这也意味着替换规则是灵活可变的。
根据文档,传入的函数定义如下:
Possible name
Supplied value
match
The matched substring. (Corresponds to $& above.)
p1, p2, …
The nth parenthesized submatch string, provided the first argument to replace() was a RegExp object. (Corresponds to $1, $2, etc. above.) For example, if /(\a+)(\b+)/, was given, p1 is the match for \a+, and p2 for \b+.
offset
The offset of the matched substring within the whole string being examined. (For example, if the whole string was ‘abcd’, and the matched substring was ‘bc’, then this argument will be 1.)
string
The whole string being examined.
那么通过该函数可以得到//开始的字符串match,由于在match中可能存在多个//,我们需要找到在match中第一个前缀不为:的//位置,从该位置开始的内容皆为代码注释。
优化后的deleteCodeComments()函数具体的实现和逻辑说明见如下代码:
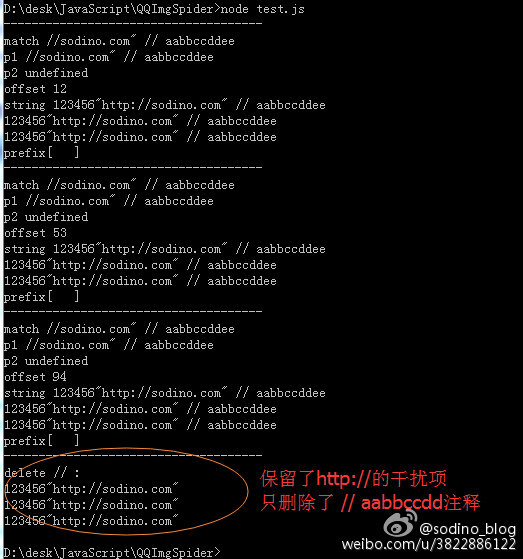
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 function deleteCodeComments(code) { var reg = /(\/\/.*)?|(\/\*[\s\S]*?\*\/)/g; var result = code.replace(reg, (match, p1, p2, offset, string) => { // match: 正则表达式匹配到的目标字符串 // p1: 表达式中第一备选的目标字符串,即单行注释 // p1: 表达式中第二备选的目标字符串,即多行注释 // offset: 匹配到的目标字符串在源字符串的起始位置 // string: 源字符串 var target = ''; if (p1 != undefined && p1 != null && p1.length > 0) { console.log('-------------------------------------'); console.log('match', match); console.log('p1', p1); console.log('p2', p2); console.log('offset', offset); console.log('string', string); if (offset == 0) { // 匹配字符串起始就是'//',所以整行都是注释 return target; } console.log('no return!!??'); // 获取当前字符串中第一个纯正的单选注释'//' var idxSlash = 0; while ((idxSlash = match.indexOf('//', idxSlash)) >= 0 ){ var prefix = string.charAt(offset + idxSlash -1); if (prefix === ':') { // 前一个字符是':',所以不是单行注释 idxSlash = idxSlash + '//'.length; continue; } else { target = match.substring(0, idxSlash) break; } }; } return target; }); return result; } function deleteCodeComments(code) { // 另一种思路更简便的办法 // 将'://'全部替换为特殊字符,删除注释代码后再将其恢复回来 var tmp1 = ':\/\/'; var regTmp1 = /:\/\//g; var tmp2 = '@:@/@/@'; var regTmp2 = /@:@\/@\/@/g; code = code.replace(regTmp1, tmp2); var reg = /(\/\/.*)?|(\/\*[\s\S]*?\*\/)/g; code = code.replace(reg, ''); result = code.replace(regTmp2, tmp1); return result; } string = '123456"http://sodino.com" // aabbcc http://sodino.com'; string = string + '\n\r' + string + '\n\r' + string; // result = string.replace(/\/\/.*/g, ""); result = deleteCodeComments(string); console.log('-------------------------------------'); console.log('delete // :'); console.log(result);
运行效果如下图:
About Sodino