【C/C++】多进程:子进程的创建fork()
文章结构:
#进程结构
Linux下一个进程在内存里有三部分的数据,就是”代码段”、”堆栈段”和”数据段”。接触过汇编语言的人了解,一般的CPU都有上述三种段寄存器,以方便操作系统的运行。这三个部分也是构成一个完整的执行序列的必要的部分。
“代码段”,顾名思义,就是存放了程序代码的数据,如果机器中有数个进程运行相同的一个程序,那么它们就可以使用相同的代码段。”堆栈段”存放的就是子程序的返回地址、子程序的参数以及程序的局部变量。而数据段则存放程序的全局变量,常数以及动态数据分配的数据空间(比如用malloc之类的函数取得的空间)。这其中有许多细节问题,这里限于篇幅就不多介绍了。系统如果同时运行数个相同的程序,它们之间就不能使用同一个堆栈段和数据段。
有两个基本的操作用于创建和修改进程:函数fork()用来创建一个新的进程,该进程几乎是当前进程的一个完全拷贝,利用了父进程的代码段、堆栈段、数据段,当父子进程中对共有的数据段进行重新设值或调用不同方法时,才会导致数据段及堆栈段的不同;函数族exec()用来启动另外的进程以取代当前运行的进程,除了PID仍是原来的值外,代码段、堆栈段、数据段已经完全被改写了。
引用自CNBlog
#include <unistd.h>
pid_t fork(void); 当执行fork()函数后,会生成一个子进程,子进程的执行从fork()的返回值开始且代码继续往下执行。
所以fork()执行一次后会有两次返回值:第一次为原来的进程,即父进程会有一次返回值,表示新生成的子进程的进程ID;第二次为子进程的起始执行,返回值为0。
如果返回值为-1,则表示创建子进程失败,可能通过errno定位失败原因。
#示例代码
以下代码演示了fork()创建一个子进程,及如何根据返回值区分主进程与子进程等。
1 |
|
以上代码中,使用fork()创建了一个子进程。返回值pId有两个作用:一是判断fork()是否正常执行;二是判断fork()正常执行后如何区分父子进程。
在父子进程中,都各自打印出自己的进程ID及父/子进程ID。
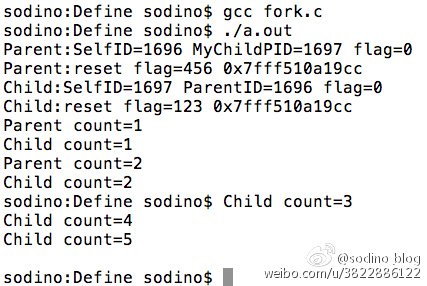
通过flag的值可以验证创建的子进程是完全复制父进程的堆栈段(因为flag是在main()方法内声明的)的,两个进程都输出了flag=0的信息。接下来进程可以各自对flag再次更新值,做到了互不干扰。但从打印的int指针地址来看,指针地址值都是一样的,再次印证了子进程是对父进程的完全复制。
接下来,父进程只执行了两次打印,然后就结束且进程销毁退出了;但父进程的结束并不影响子进程的运行,子进程一直打印到数字5才正常退出。所以验证了fork()出来的进程是各自独立的,完全按照自己的代码逻辑运行直至执行完毕。
以下是运行效果截图。
- 守护进程
有时为了保护主进程不被杀,或者主进程异外退出后仍可再次启动(或后台运行),就执行fork()让子进程监控主进程的运行状态,根据监听保护主进程的运行。
好多应用会用进程间的相对独立性再做点黑产的事..嗻嗻..就不说了。
- 框架扩展
主进程只负责生成子进程,派出子进程去执行应用框架下的子任务,这些任务可能多变、可能更新频繁,但配合fork()及exec()函数,一切都是so easy..还保证了主进程的稳定,避免频繁更新程序。
下一篇内容:多进程:父进程监听子进程状态 wait()的使用