作为新手,碰到问题了就google了一下,网上已经有teary:window下nodejs爬取gb2312网页出现乱码的解决方案出来了。
本文和上面的作法几乎相同,只是自己不想引用bufferhelper,自己用JavaScript原生的Buffer替代实现了。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| var http = require("http");
var iconv = require('iconv-lite');
var url = 'http://www.qq.com/';
http.get(url, function(res){
var arrBuf = [];
var bufLength = 0;
res.on("data", function(chunk){
arrBuf.push(chunk);
bufLength += chunk.length;
})
.on("end", function(){
// arrBuf是个存byte数据块的数组,byte数据块可以转为字符串,数组可不行
// bufferhelper也就是替你计算了bufLength而已
var chunkAll = Buffer.concat(arrBuf, bufLength);
var strJson = iconv.decode(chunkAll,'gb2312'); // 汉字不乱码
console.log(strJson);
});
});
|
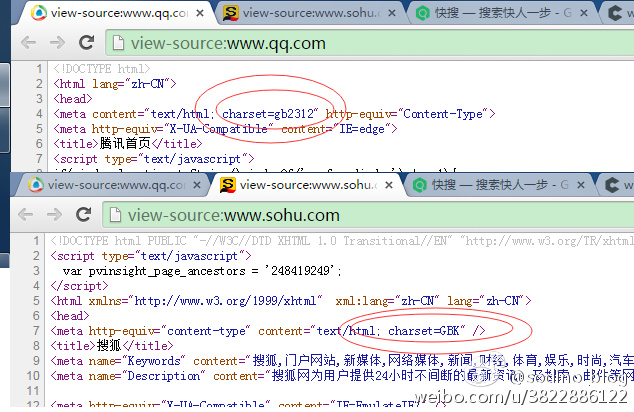
GB2312编码的网页链接有:腾讯主页;GBK编码的网页链接有:搜狐主页。
怎么查看网页是哪些编码呢?可以直接浏览器打开然后右键查看源代码,在meta标签中去查看Content-Type就好了.如下图.
About Sodino